Adaptive Anonymisierung
Unsere Lösung basiert auf einem generischen Framework, welches relevante Verfahren der Anonymisierung (Generalisierung, Blocken, K-Anonymity, Differential Privacy u.a.) zur Verfügung stellt. Anhand der Datenstruktur und dem gefordertem Nutzungsgrad der Daten erfolgt die kunden- bzw. anwendungsspezifische Anpassung des Frameworks in einem iterativen Prozess.
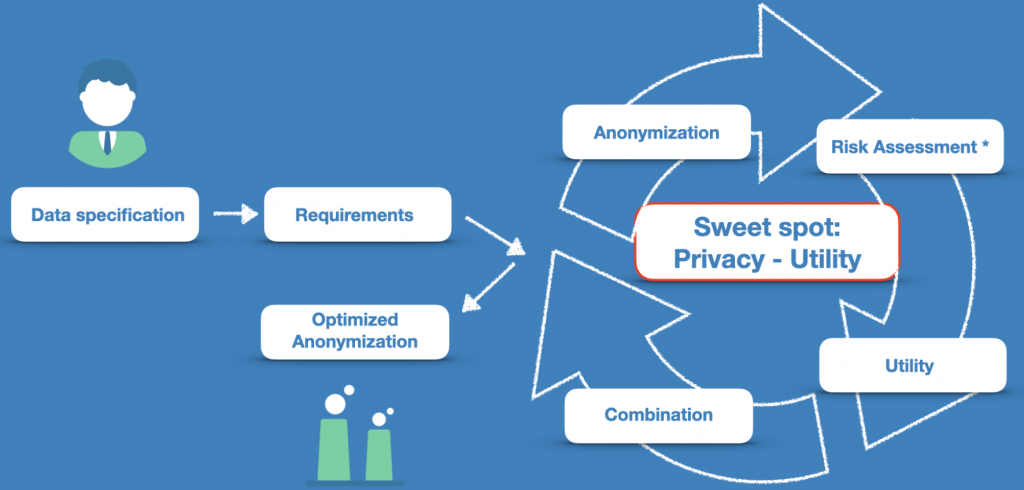
Eine systematische und objektive Risikoberechnung der De-Anonymisierung ermöglicht unsere statistische Re-Identifizierungsanalyse. Damit wird das Risiko im Kontext vorhandener Daten, ggf. auch weiteren externen Daten sowie möglichen Angriffsszenarien quantifiziert. Kombiniert mit der bestmögliche Kombination verschiedenster Anonymsierungstechniken finden wir so den Sweet Spot zwischen Privacy und Utility.
Durch die dynamische Natur vieler Anwendungsfälle verändern sich Datensätze, Datenstrukturen, aber auch die Anforderungen häufig. Unsere Lösung beinhaltet die regelmäßige (automatische) Prüfung der gewählten Verfahren und des Re-Identifizierungsrisikos und ist so die Grundlage für kontinuierliche DSGVO-Compliance, da jederzeit das bestmögliche Vorgehen gewählt und dokumentiert wird.