Adaptive Anonymization
Our solution is based on a generic framework, which provides relevant methods of anonymization (generalization, blocking, K-anonymity, differential privacy, etc.). Based on the data structure and the required degree of utilization of the data, the customer or application-specific adaptation of the framework takes place in an iterative process.
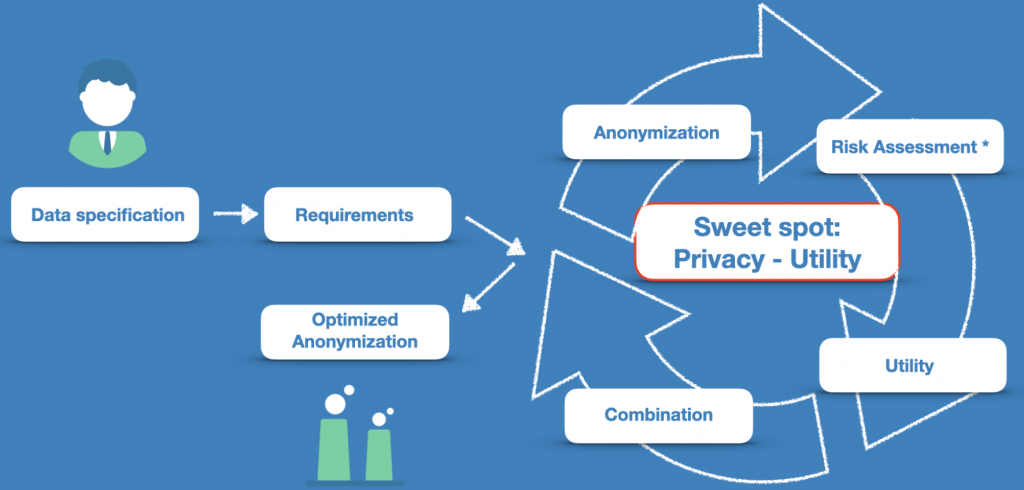
Our statistical re-identification analysis enables a systematic and objective risk calculation of the de-anonymization. This quantifies the risk in the context of existing data, possibly also other external data and possible attack scenarios. Combined with the best possible combination of different anonymization techniques, we find the sweet spot between privacy and utility.
Due to the dynamic nature of many use cases, data sets, data structures, but also the requirements change frequently. Our solution includes the regular (automatic) review of the selected procedures and the re-identification risk and is thus the basis for continuous GDPR compliance, as the best possible procedure is selected and documented at all times.